
deepseek 模型各版本硬件要求
目前DeepSeek-R1系列模型在Huggingface上共计开源了8种。
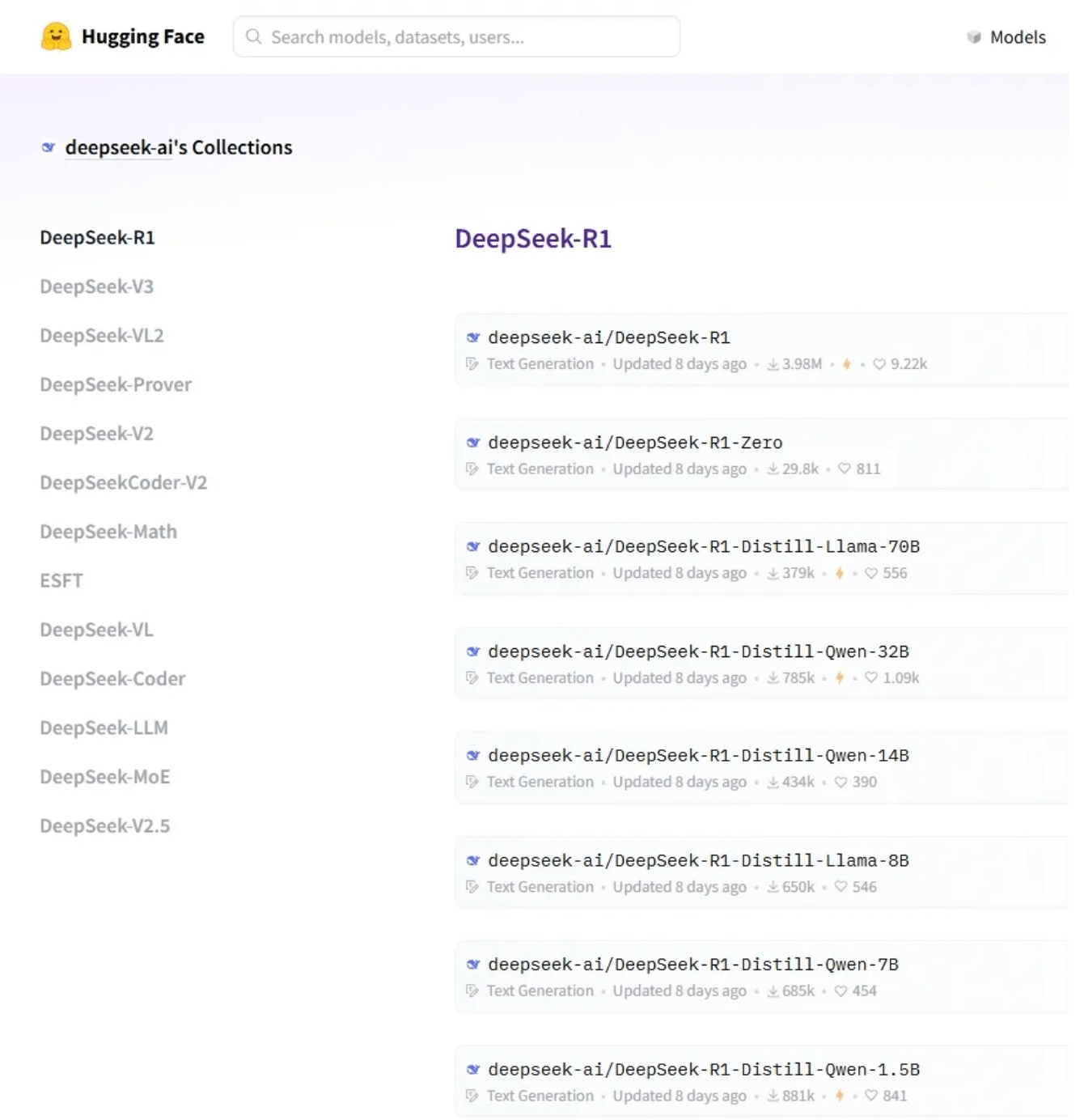
DeepSeek-R1系列的两大明星产品:
DeepSeek-R1-Zero:AI界的"极限探索者"
• 超强算力:6710亿参数(采用MoE架构,每个token可调动370亿参数)
• 创新训练:采用纯强化学习的端到端训练方式
• 突破性能:实现自我验证、长链推理等前沿能力
• 实战表现:在AIME 2024基准测试中取得71%的亮眼成绩
DeepSeek-R1:AI界的"全能冠军"
• 强大算力:同样拥有6710亿参数的超强实力
• 独特训练:创新性采用多阶段混合训练方法
• 双重加持:结合监督微调冷启动与强化学习优化
• 卓越成就:在AIME 2024测试中达到79.8%的惊人准确率
值得一提的是,DeepSeek团队通过知识蒸馏技术,成功将这些顶级模型的能力传承给更轻量级的版本。这种创新方式不仅大幅降低了模型应用门槛,还提升了小型模型的推理能力,这正是DeepSeek在AI领域备受瞩目的重要原因之一。DeepSeek-R1 蒸馏模型的几款小尺寸模型,是使用 DeepSeek-R1 生成的包含<think>...</think>标记的思考链数据进行微调后的蒸馏版本,继承了 R1的推理能力。
注意:以下是针对DeepSeek-R1 模型各版本的硬件要求指南,涵盖训练、推理及不同规模的模型需求。实际需求可能因具体任务、框架优化和并行策略有所差异,建议结合自身场景调整配置。
deepseek 精简版
模型简介
参数量:1.5B、3B
适用场景:嵌入式设备、边缘计算、实时响应场景(如客服机器人)。
硬件要求
训练阶段
GPU: 1x RTX 3060(12GB显存)或 Tesla T4
显存: ≥8GB(FP32训练)
内存: ≥32GB DDR4
推理阶段
GPU: 集成显卡(如Intel Iris Xe)或 Jetson Nano(需INT8量化)
CPU: 4核 + 16GB内存(3B模型)
移动端: 支持通过TensorRT转换至Android/iOS(模型需剪枝+量化)
使用阶段
GPU: 4GB 左右 GTX 1050
CPU: 4核 + 8GB内存
移动端: 支持通过TensorRT转换至Android/iOS(模型需剪枝+量化)
deepseek基础版本
模型简介
参数量:7B、8B、13B、14B
适用场景:通用文本生成、对话系统、中等复杂度的推理任务。
硬件要求
训练阶段
GPU: 至少 1x NVIDIA A100 40GB(单卡训练需开启梯度检查点优化)
多卡训练: 推荐 4x A100 80GB(使用ZeRO-3优化并行策略)
显存: 单卡需 ≥24GB(FP16精度)
内存: ≥64GB DDR4
存储: ≥500GB NVMe SSD(用于高速数据加载)
推理阶段
GPU: 1x RTX 3090/4090(24GB显存)或 T4(16GB显存,需量化至INT8)
显存: 7B模型需 ≥10GB(FP16),13B模型需 ≥16GB(INT4量化)
CPU备用方案: 需 ≥32核 + 128GB内存(速度显著低于GPU)
使用阶段
优化建议
使用模型量化(如GPTQ、AWQ)降低显存占用。
启用FlashAttention-2加速注意力计算。
deepseek大型版本
模型简介
参数量:32B、70B
适用场景:复杂逻辑推理、长文本生成、专业领域任务(法律、代码等)。
硬件要求
训练阶段
GPU: 必须多卡并行,推荐 8x A100 80GB 或 H100(结合Tensor并行+流水线并行)
显存: 单卡 ≥40GB(FP16 + ZeRO-3优化)
内存: ≥256GB DDR4 ECC
存储: ≥1TB NVMe SSD(数据集较大时需扩容)
推理阶段
GPU: 2x A100 40GB(33B模型)或 4x A100 80GB(70B模型,FP16)
量化支持: 70B模型INT4量化后可在 2x RTX 4090(24GBx2)运行
CPU备用方案: 需 ≥64核 + 256GB内存(延迟较高,仅适合批量处理)
使用阶段
优化建议
使用模型切分(如DeepSpeed-Inference)跨多卡加载。
采用vLLM推理框架提升吞吐量。
deepseek超大型版本
超大规模集群(如 100B+ 参数)
硬件配置
GPU节点:64x H100(结合NVLink互连)
网络:InfiniBand HDR(200Gbps)
存储:分布式文件系统(如Lustre)
框架支持
使用Megatron-LM + DeepSpeed 实现3D并行(数据/流水线/张量并行)。
使用建议
注意事项及显存计算公式
显存估算公式
如何准确计算大模型所需的显存大小,是许多开发者经常遇到的问题。掌握GPU内存的估算方法,并据此合理配置硬件资源以支持模型运行,是确保大模型成功部署和扩展的关键。这一能力也是衡量开发者对大模型生产环境部署和可扩展性理解程度的重要指标。
要估算服务大型语言模型所需的 GPU 内存,可以使用以下公式:
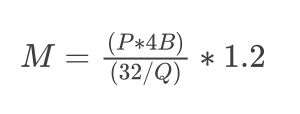
• M是所需的 GPU 显卡内存(单位:GB千兆字节)。
• P是模型中的参数数量,表示模型的大小。例如 deepseek-R1 671B模型有 6710 亿(671*109)个参数,则该值将为 671。
• 4B表示每个参数使用 4 个字节。每个参数通常需要 4 个字节的内存。这是因为浮点精度通常占用 4 个字节(32 位)。但是,如果使用半精度(16 位),则计算将相应调整。
• Q是加载模型的位数(例如,16 位或 32 位)。根据以 16 位还是 32 位精度加载模型,此值将会发生变化。16 位精度在许多大模型部署中很常见,因为它可以减少内存使用量,同时保持足够的准确性。
• 1.2 乘数增加了 20% 的开销,以解决推理期间使用的额外内存问题。这不仅仅是一个安全缓冲区;它对于覆盖模型执行期间激活和其他中间结果所需的内存至关重要。
举例:以满血版DeepSeek-R1(671B参数、加载 16 位精度)为例,计算其推理所需的显存
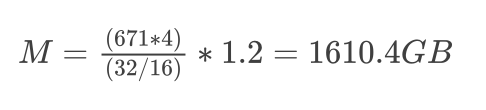
这个计算告诉我们,需要大约1610.4 GB 的 GPU 显存来为 16 位模式下具有 6710 亿个参数的满血版 DeepSeek-R1 大模型提供推理服务。
因此,单个具有 80 GB 显存的 NVIDIA A100 GPU 或者 H00 GPU 不足以满足此模型的需求,需要至少20张具有 80 GB 内存的 A100 GPU 才能有效处理内存负载。此外,仅加载 CUDA 内核就会消耗 1-2GB 的内存。实际上,无法仅使用参数填满整个 GPU 显存作为估算依据。如果是训练大模型,则需要更多的 GPU 显存,因为优化器状态、梯度和前向激活每个参数都需要额外的内存。
量化影响:
INT8量化可减少50%显存,但可能损失3-5%精度;
INT4量化显存降低75%,适合对延迟敏感的推理场景。
散热与功耗:
多卡训练时需确保电源(如单A100卡功耗≥300W)和散热系统稳定。
总结建议
个人开发者/小型团队:选择1B/7B版本,搭配RTX 3090/4090。
企业级部署:使用33B/70B版本,配置A100/H100集群。
边缘设备:优先采用3B量化版 + TensorRT优化。
