linux服务器上分析系统性能常见的命令
当你发现 Linux 服务器上的系统性能问题,在最开始的 1 分钟时间里,你会查看哪些系统指标呢?在这篇文章里你可以使用下面这 10 个命令行了解系统整体的运行情况,以及当前运行的进程对资源的使用情况。
在这些指标里面,我们先关注和错误、以及和资源饱和率相关的指标,然后再看资源使用率。相对来讲,错误和资源饱和率比较容易理解。饱和的意思是指一个资源(CPU,内存,磁盘)上的负载超过了它能够处理的能力,这时候我们观察到的现象就是请求队列开始堆积,或者请求等待的时间变长。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top有些命令行依赖于 sysstat 包。通过这些命令行的使用,你可以熟悉一下分析系统性能问题时常用的一套方法或者流程:USE 。这个方法主要从资源使用率(Utilization)、资源饱和度(Satuation)、错误(Error),这三个方面对所有的资源进行分析(CPU,内存,磁盘等等)。在这个分析的过程中,我们也要时刻注意我们已经排除过的资源问题,以便缩小我们定位的范围,给下一步的定位提供更明确的方向。
下面的章节对每个命令行做了一个说明,并且使用了我们在生产环境的数据作为例子。对这些命令行更详细的描述,请查看相应的帮助文档。
1、uptime
[root@jms ~]# uptime
13:39:43 up 163 days, 3:57, 1 user, load average: 0.17, 0.11, 0.07这个命令能很快地检查系统平均负载,你可以认为这个负载的值显示的是有多少任务在等待运行。在 Linux 系统里,这包含了想要或者正在使用 CPU 的任务,以及在 io 上被阻塞的任务。这个命令能使我们对系统的全局状态有一个大致的了解,但是我们依然需要使用其它工具获取更多的信息。
这三个值是系统计算的 1 分钟、5 分钟、15 分钟的指数加权的动态平均值,可以简单地认为就是这个时间段内的平均值。根据这三个值,我们可以了解系统负载随时间的变化。比如,假设现在系统出了问题,你去查看这三个值,发现 1 分钟的负载值比 15 分钟的负载值要小很多,那么你很有可能已经错过了系统出问题的时间点。
假如负载的平均值显示 1 分钟为 30,比 15 分钟的 19 相比增长较多。有很多原因会导致负载的增加,也许是 CPU 不够用了;vmstat 或者 mpstat 可以进一步确认问题在哪里。
2、dmesg | tail
[root@jms ~]# dmesg | tail
[11844673.395112] UDP: bad checksum. From 172.16.17.232:52720 to 172.16.10.124:53 ulen 52
[12183558.969965] UDP: bad checksum. From 172.16.17.233:51781 to 172.16.10.124:53 ulen 46
[12204559.468725] UDP: bad checksum. From 172.16.17.233:59663 to 172.16.10.124:53 ulen 39
[12353503.605490] UDP: bad checksum. From 172.16.17.222:55118 to 172.16.10.124:53 ulen 72
[12554184.951931] UDP: bad checksum. From 172.16.17.249:55733 to 172.16.10.124:53 ulen 51
[13147104.471219] UDP: bad checksum. From 172.16.17.232:55063 to 172.16.10.124:53 ulen 65
[13405777.450310] UDP: short packet: From 172.16.17.222:59869 76/44 to 172.16.10.124:53
[13566644.667226] UDP: bad checksum. From 172.16.17.76:55659 to 172.16.10.124:53 ulen 40
[13670701.482220] UDP: bad checksum. From 172.16.17.232:54030 to 172.16.10.124:53 ulen 57
[13754471.185399] UDP: bad checksum. From 172.16.17.76:54773 to 172.16.10.124:53 ulen 50这个命令显示了最新的几条系统日志。这里我们主要找一下有没有一些系统错误会导致性能的问题。比如 oom-killer 以及 TCP 丢包。上面的例子包含了UDP 校验和(Checksum)错误或涉及 DNS 通信的问题,不要略过这一步!dmesg 永远值得看一看。
3、vmstat 1
[root@jms ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 4745300 2104 10055668 0 0 0 7 1 1 1 0 99 0 0
0 0 0 4745152 2104 10055744 0 0 0 0 353 502 0 0 100 0 0
0 0 0 4745152 2104 10055744 0 0 0 0 393 548 1 0 100 0 0
0 0 0 4745152 2104 10055760 0 0 0 0 369 392 0 0 100 0 0
0 0 0 4745120 2104 10055764 0 0 0 0 766 847 1 1 99 0 0
^Cvmstat 展示了虚拟内存、CPU 的一些情况。上面这个例子里命令行的 1 表示每隔 1 秒钟显示一次。在这个版本的 vmstat 里,第一行表示了这一次启动以来的各项指标,我们可以暂时忽略掉第一行。
需要查看的指标:
r:处在 runnable 状态的任务,包括正在运行的任务和等待运行的任务。这个值比平均负载能更好地看出 CPU 是否饱和。这个值不包含等待 io 相关的任务。当 r 的值比当前 CPU 个数要大的时候,系统就处于饱和状态了。
free:以 KB 计算的空闲内存大小。
si,so:换入换出的内存页。如果这两个值非零,表示内存不够了。
us,sy,id,wa,st:CPU 时间的各项指标(对所有 CPU 取均值),分别表示:用户态时间,内核态时间,空闲时间,等待 io,偷取时间(在虚拟化环境下系统在其它租户上的开销)
把用户态 CPU 时间(us)和内核态 CPU 时间(sy)加起来,我们可以进一步确认 CPU 是否繁忙。等待 IO 的时间(wa)高的话,表示磁盘是瓶颈;注意,这个也被包含在空闲时间里面(id), CPU 这个时候也是空闲的,任务此时阻塞在磁盘 IO 上了。你可以把等待 IO 的时间(wa)看做另一种形式的 CPU 空闲,它可以告诉你 CPU 为什么是空闲的。
系统处理 IO 的时候,肯定是会消耗内核态时间(sy)的。如果内核态时间较多的话,比如超过 20%,我们需要进一步分析,也许内核对 IO 的处理效率不高。
在上面这个例子里,CPU 时间大部分都消耗在了用户态,表明主要是应用层的代码在使用 CPU。CPU 利用率(us + sy)也超过了 90%,这不一定是一个问题;我们可以通过 r 和 CPU 个数确定 CPU 的饱和度。
4、mpstat -P ALL 1
[root@jms ~]# mpstat -P ALL 1
Linux 3.10.0-1160.el7.x86_64 (jms) 03/11/2025 _x86_64_ (4 CPU)
02:22:43 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:22:44 PM all 1.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.75
02:22:44 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
02:22:44 PM 1 1.98 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 97.03
02:22:44 PM 2 1.98 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.02
02:22:44 PM 3 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00
02:22:44 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:22:45 PM all 0.50 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.50
02:22:45 PM 0 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.00
02:22:45 PM 1 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.00
02:22:45 PM 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
02:22:45 PM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
02:22:45 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:22:46 PM all 1.51 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.99
02:22:46 PM 0 3.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
02:22:46 PM 1 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.99
02:22:46 PM 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
02:22:46 PM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
^C这个命令把每个 CPU 的时间都打印出来,可以看看 CPU 对任务的处理是否均匀。比如,如果某一单个 CPU 使用率很高的话,说明这是一个单线程应用。
5、pidstat 1
[root@jms ~]# pidstat 1
Linux 3.10.0-1160.el7.x86_64 (jms) 03/11/2025 _x86_64_ (4 CPU)
02:23:41 PM UID PID %usr %system %guest %CPU CPU Command
02:23:42 PM 0 809 0.00 0.98 0.00 0.98 1 irqbalance
02:23:42 PM 0 2173 0.98 0.00 0.00 0.98 3 prometheus
02:23:42 PM 0 25388 0.00 0.98 0.00 0.98 3 pidstat
02:23:42 PM UID PID %usr %system %guest %CPU CPU Command
02:23:43 PM 0 25388 0.00 1.00 0.00 1.00 3 pidstat
^Cpidstat 和 top 很像,不同的是它可以每隔一个间隔打印一次,而不是像 top 那样每次都清屏。这个命令可以方便地查看进程可能存在的行为模式,你也可以直接 copy past,可以方便地记录随着时间的变化,各个进程运行状况的变化。
6、iostat -xz 1
[root@jms ~]# iostat -xz 1
Linux 3.10.0-1160.el7.x86_64 (jms) 03/11/2025 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.86 0.00 0.18 0.00 0.00 98.96
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.01 0.00 0.31 0.14 28.96 185.40 0.00 0.72 0.38 0.72 0.24 0.01
scd0 0.00 0.00 0.00 0.00 0.00 0.00 114.22 0.00 0.44 0.44 0.00 0.44 0.00
dm-0 0.00 0.00 0.00 0.32 0.14 28.96 179.83 0.00 0.71 0.42 0.71 0.25 0.01
avg-cpu: %user %nice %system %iowait %steal %idle
0.75 0.00 0.25 0.00 0.00 99.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.25 0.00 0.00 99.75
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
avg-cpu: %user %nice %system %iowait %steal %idle
0.25 0.00 0.25 0.00 0.00 99.50
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
^Ciostat 是理解块设备(磁盘)的当前负载和性能的重要工具。几个指标的含义:
r/s,w/s,rkB/s,wkB/s:系统发往设备的每秒的读次数、每秒写次数、每秒读的数据量、每秒写的数据量。这几个指标反映的是系统的工作负载。系统的性能问题很有可能就是负载太大。
await:系统发往 IO 设备的请求的平均响应时间。这包括请求排队的时间,以及请求处理的时间。超过经验值的平均响应时间表明设备处于饱和状态,或者设备有问题。
avgqu-sz:设备请求队列的平均长度。队列长度大于 1 表示设备处于饱和状态。
%util:设备利用率。设备繁忙的程度,表示每一秒之内,设备处理 IO 的时间占比。大于 60% 的利用率通常会导致性能问题(可以通过 await 看到),但是每种设备也会有有所不同。接近 100% 的利用率表明磁盘处于饱和状态。
如果这个块设备是一个逻辑块设备,这个逻辑快设备后面有很多物理的磁盘的话,100% 利用率只能表明有些 IO 的处理时间达到了 100%;后端的物理磁盘可能远远没有达到饱和状态,可以处理更多的负载。
还有一点需要注意的是,较差的磁盘 IO 性能并不一定意味着应用程序会有问题。应用程序可以有许多方法执行异步 IO,而不会阻塞在 IO 上面;应用程序也可以使用诸如预读取,写缓冲等技术降低 IO 延迟对自身的影响。
7、free -m
[root@jms ~]# free -m
total used free shared buff/cache available
Mem: 16046 1591 4430 107 10024 14017
Swap: 0 0 0右边的两列显式:
buffers:用于块设备 I/O 的缓冲区缓存。
cached:用于文件系统的页面缓存。
我们只是想要检查这些不接近零的大小,其可能会导致更高磁盘 I/O(使用 iostat 确认),和更糟糕的性能。上面的例子看起来还不错,每一列均有很多 M 个大小。
比起第一行,-/+ buffers/cache 提供的内存使用量会更加准确些。Linux 会把暂时用不上的内存用作缓存,一旦应用需要的时候就立刻重新分配给它。所以部分被用作缓存的内存其实也算是空闲的内存。为了解释这一点, 甚至有人专门建了个网站:http://www.linuxatemyram.com/。
如果使用 ZFS 的话,可能会有点困惑。ZFS 有自己的文件系统缓存,在 free -m 里面看不到;系统看起来空闲内存不多了,但是有可能 ZFS 有很多的缓存可用。
8、sar -n DEV 1
[root@jms ~]# sar -n DEV 1
Linux 3.10.0-1160.el7.x86_64 (jms) 03/11/2025 _x86_64_ (4 CPU)
02:28:12 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:28:13 PM br-52df3a7afc2a 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:13 PM br-0d64a254c974 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:13 PM vethfea166b 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:13 PM eth0 16.00 9.00 15.02 1.05 0.00 0.00 0.00
02:28:13 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:13 PM br-16617c607cf3 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:13 PM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C这个工具可以查看网络接口的吞吐量:rxkB/s 和 txkB/s 可以测量负载,也可以看是否达到网络流量限制了。在上面的例子里,eth0 的吞吐量达到了大约 0.015 Mbytes/s
9、sar -n TCP,ETCP 1
[root@jms ~]# sar -n TCP,ETCP 1
Linux 3.10.0-1160.el7.x86_64 (jms) 03/11/2025 _x86_64_ (4 CPU)
02:31:45 PM active/s passive/s iseg/s oseg/s
02:31:46 PM 1.00 0.00 24.00 28.00
02:31:45 PM atmptf/s estres/s retrans/s isegerr/s orsts/s
02:31:46 PM 0.00 0.00 0.00 0.00 0.00
^C这是对 TCP 重要指标的一些概括,包括:
active/s:每秒钟本地主动开启的 TCP 连接,也就是本地程序使用 connect() 系统调用
passive/s:每秒钟从源端发起的 TCP 连接,也就是本地程序使用 accept() 所接受的连接
retrans/s:每秒钟的 TCP 重传次数
atctive 和 passive 的数目通常可以用来衡量服务器的负载:接受连接的个数(passive),下游连接的个数(active)。可以简单认为 active 为出主机的连接,passive 为入主机的连接;但这个不是很严格的说法,比如 loalhost 和 localhost 之间的连接。
重传表示网络或者服务器的问题。也许是网络不稳定了,也许是服务器负载过重开始丢包了。上面这个例子表示每秒只有 1 个新连接建立。
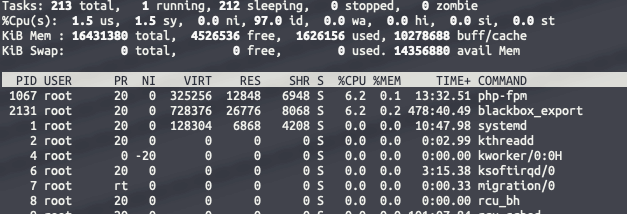
10、top
top - 14:33:06 up 163 days, 4:51, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 213 total, 1 running, 212 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.5 us, 1.5 sy, 0.0 ni, 97.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16431380 total, 4526536 free, 1626156 used, 10278688 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 14356880 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1067 root 20 0 325256 12848 6948 S 6.2 0.1 13:32.51 php-fpm
2131 root 20 0 728376 26776 8068 S 6.2 0.2 478:40.49 blackbox_export
1 root 20 0 128304 6868 4208 S 0.0 0.0 10:47.98 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:02.99 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 3:15.38 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.33 migration/0top 命令涵盖了我们前面讲述的许多指标。我们可以用它来看和我们之前查看的结果有没有很大的不同,如果有的话,那表示系统的负载在变化。
top 的缺点就是你很难找到这些指标随着时间的一些行为模式,在这种情况下,vmstat 或者 pidstat 这种可以提供滚动输出的命令是更好的方式。如果你不以足够快的速度暂停输出(Ctrl-S 暂停,Ctrl-Q 继续),一些间歇性问题的线索也可能由于被清屏而丢失。
